Research
Twice the Bits, Twice the Trouble: Vulnerabilities Induced by Migrating to 64-Bit Platforms
- -
논문 이해 전 알아야 할 내용
32비트 기반 코드에서 64비트 시스템에 포팅을 할 때, 왜 문제가 생기는가?

이러한 취약점의 두 가지 상호 의존적인 원인
(a) 정수 폭의 변경과 (b) 대량의 메모리를 할당할 수 있는 매우 큰 주소 공간
C 에서의 정수 타입
Signedness ?
C의 Integer 종류(char, short, int, long, long long)에는 모두 Signed와 Unsigned 형식이 존재.
Integer 종류 T에 대하여:
$$S(T)∈{0,1} $$
S(T)가 0인 경우에는 unsigned type임을 뜻하며, S(T)가 1의 경우에는 signed Type을 뜻함.

Signed의 경우에는 부호비트 존재, Unsigned 경우에는 부호비트 대신 그 자리를 숫자 표현용 비트로 사용.
Conversion Rank ?

Interger의 종류 T에 대해, 크기에 따른 Conversion Rank를 부여
$$ R(T)∈N, R(char) < R(short) < R(int) < R(long) < R(long long) $$
- R(A) < R(B) 일 경우에 (B의 우선 순위가 A보다 높을 때) W(A) ≤ W(B)가 성립한다.
- B의 우선순위가 A보다 높을 때, B의 폭은 A의 폭과 같거나 혹은 더 커야한다.

$$ R(A) < R(B) ,W(A) ≤ W(B) $$
Width & Range ?
Conversion Rank는 integer 종류를 크기에 따라 정렬. Conversion Rank는 대소관계를 비교해줄 뿐, 정확한 interger 종류 마다의 범위(Range)는
Data Model에 의해 정해짐. T(interger)에 대해 width(폭)은 아래와 같음
$$ W(T)∈{1,2,4,8} $$
T를 알 때, W를 구하는 방법은 알았으니, W와 S를 통해 T를 구할 수 있다. 아래 식 참조.
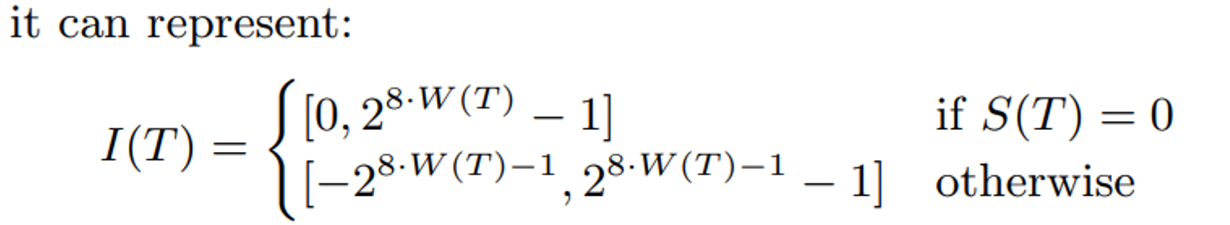
Data Model
- Data Model은 Operating System에 따른 Interger의 Width를 결정함.
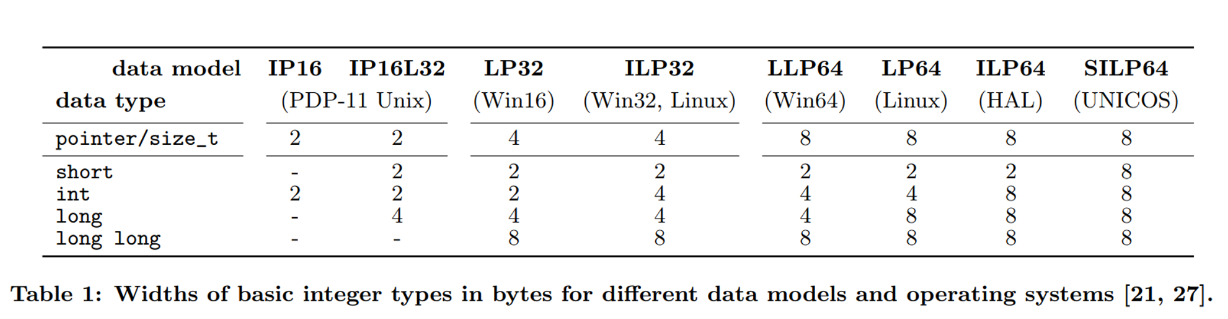

- 모든 Model의 SIZE_T(크기)의 크기는 해당 아키텍쳐의 레지스터 크기와 동일 그러나, 같은 Integer Type임에도 사용하는 메모리 크기가 달라짐(ILP32 vs LP64)
Integer-Related Vulnerabilities
Integer - truncations / underflows / overflows / Signedness

Integer Truncations ?
- Integer Truncations는 Width가 더 큰 값이 Width가 더 작은 값에 타입캐스팅 하려할 때 발생
unsigned int x = attacker_controlled();
unsigned short y = x;
char *buffer = malloc(y);
memcpy(buffer, src, x);- 위 코드에서 x는 4바이트, y는 2바이트. y라는 2바이트짜리 바구니에 4바이트짜리 x를 대입하려 시도하면,
상위 2바이트가 소실.
예를 들어 x가 0xFFFFFFFF일 때, 2바이트인 y에 x를 대입하면 x = 0x0000FFFF가 됨.
이 때, malloc 함수에서는 0xFFFF 만큼만 할당하는 Truncations가 발생
memcpy에서는 x가 len(길이)기 때문에, 0xFFFF의 크기의 Buffer에
0xFFFFFFFF만큼 써버리는 Buffer Overflow가 발생하게 된다. (Truncations ⇒ Overflow) - 이 취약점의 Key Point는 Integer Type의 Width에 의해 발생하는 것이기 때문에, data Model에 따라서 취약점이 발생하는지 안하는지 결정되는 것이다.
Integer Overflow?
- Integer Overflow란 연산의 결과 값을 A, 할당 받을 Integer Type을 T라고 했을 때, W(A) > W(T) 일 때 발생함.
unsigned int x = attacker_controlled();
char *buffer = malloc(x+CONST);
memcpy(buffer, src, x);- x에 0xFFFFFFFF, Const의 값이 0x100으로 Fixed 되어 있다고 가정하였을 때, malloc의 인잣 값에는 SIZE_T(4바이트)가 들어가야하므로 0xFF가 할당됨. 그러나 memcpy에서는 x에 0x100을 더하지 않는 값을 그대로 memcpy하려하므로 더 큰 값이 memcpy되면서 Buffer Overflow가 발생함.
- 이 취약점 또한 Data Model이 결정하기에(SIZE_T) integer Overflow도 Data Model에 따라 취약점의 발생 유무가 가려진다.
- UnderFlow의 경우에는 Vice-Versa(반대로 생각)
Integer Signedness?
short x = attacker_controlled();
char *buffer = malloc((unsigned short) x);
memcpy(buffer, src, x);
- 잘못 된 Sign-Extension으로 인해 Buffer Overflow가 발생하는 예제 x에 -1이 들어가는 순간,(unsigned shor)로 형변환되어 0x0000FFFF만큼 malloc 인잣값에 들어가서 0xFFFF만큼 할당.
- memcpy에서는 0xFFFFFFFF(SIZE_T)만큼 메모리에 접근하려하기 때문에 오버플로우가 발생함.
Interger Signedness On Checking
int x = attacker_controlled();
unsigned short BUF_SIZE = 10;
if(x >= BUF_SIZE)
return;
memcpy(buffer, src, x);
- x는 부호화 된 int 변수이므로, x에 -1을 대입하는 것으로 우회할 수 있음.
- x에 -1을 대입했을 때, if문에서는 부호화 된 값이기에 거짓이 반환되고, memcpy에서 3번째 인잣값은 SIZE_T이므로 부호화 되지 않아 0xFFFFFFFF만큼 읽어버림.
- 아래 내용 참조

논문 이해
64-Bit Migration Vulnerabilities
- 정수 관련 결함은 과거에 매우 상세하게 연구되어 왔으며, 이를 분석하고 고치기 위해 여러가지 방법을 찾아왔음. 그러나 이러한 접근 방식은 모두 잘못 된 타입 캐스팅 같이 개발자가 직접 생성한 코드의 결함에 집중되어 있음. 이 논문은 32비트에서 취약하지 않은 코드가 어떻게 64비트에서 취약할 수 있는지 소개함.
- 이러한 취약점은 Integer의 너비 변경(W) 과 더 큰 주소 공간 사용 때문에 발생함.
Effects of Integer Width Changes ?
Incorrect Pointer Differences
char buf[MAX_LINE_SIZE];
char *eol = strchr(str, ’\\n’);
*eol = ’\\0’;
unsigned int len = eol - str;
if(len >= MAX_LINE_SIZE)
return -1;
**strcpy(buf, str);**
- 위 코드는 32Bit 운영체제에서는 WILP32(int) = WILP32(ptrdiff_t) 이기 때문에 아무런 문제가 발생하지 않지만, 64비트 운영체제에서는 WILP32(int) < WILP32(ptrdiff_t)이기 때문에 문제가 발생.
- 💡 “This is unproblematic on all 32-bit platforms, since WILP32(int) = WILP32(ptrdiff_t), but fatal on LP64 and LLP64, where WM(int) < WM(ptrdiff_t) for M ∈ {LP64, LLP64}”
Casting Pointers to integers(위 내용에서 이어짐)
- 32bit에서는 Pointer의 W(width)와, int의 W(width)가 같아서 문제가 발생하지 않는다.
- 그러므로 권장되는 것은 아니다만, int형 변수에 포인터를 적용해도 딱히 상관없다(32bit)
- 64비트의 경우에는 uint64_t를 사용하면 된다고 한다
- 그러나, 64bit에서는 Pointer의 width가 len의 크기보다 더 크다.
- MAX_LINE_SIZE = 100이고, Len의 값을 할당하는 eol - str = 0x1000000ff 일 경우( 큰 차이를 가질 경우에는) len은 0xFF로 잘린 값을 갖게 되고, 그 결과로 7행에서 오버플로가 발생하게 된다.

- 위 논문 내용 중에서 처음 4GB를 넘어가지 않는 경우에는 truncation이 발생하지 않는다고 되어있다. 이 말은 즉슨, 프로그램이 4gb이상의 메모리를 할당해서 사용하고 있어야한다는 뜻이 되고, ASLR등의 주소 공간 레이아웃 임의화 등의 보호기법 때문에 실제로 공격에 쓰이기는 어렵다.
Attackers, however,
may purposely increase the amount of memory allocated by
the program to ensure that pointers outside this safe range
are created. Still, these vulnerabilities are rather rare and a
successful exploitation is rendered difficult by address space layout
randomization (ASLR). -논문 내용 중 발췌-
Sign Extension
- 부호가 있는 유형 (Signed)에서 더 넓은 부호가 있는 유형으로 변환되거나, 부호가 있는 유형(Signed)에서 같은 부호가 없는 유형으로 변환될 때 일어남.
- 결과적으로 음수가 할당될 때, 부호 없는 유형에서는 이를 매우 큰 양수를 변환하여 의도치 않는 오버플로우나 Trucation이 발생할 수 있음.

- 추가적으로, signed 정수가 ILP32에서 width보다 더 넓은 unsigned 형식으로 변환될 때, 이 문제가 일어날 수 있음. ILP32 → LLP64로 변환할 때는 int와 long 형식에서 SIZE_T 형식으로 변환 할때, LP64의 경우엔 int에서 unsigned long, SIZE_T로 변환 할 때 위 문제가 일어남. 아래 표 참고.
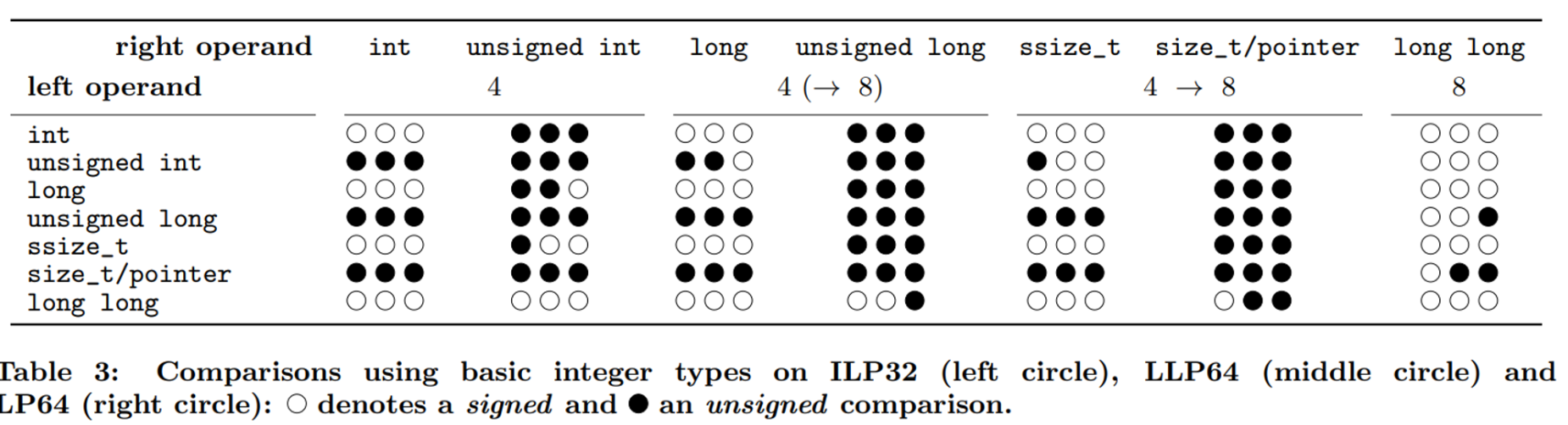
💡 ILP32 → LLP64, ILP32 → LP64 모두 SIZE_T 변환에서 문제가 발생함으로, 이를 주시하면 좋다.

Signedness Of Comparisons(BOF Check Failure)
#include <stdio.h>
#include <string.h>
#include <malloc.h>
#include <cstdint>
const unsigned int BUF = 128;
long len = -1;
void main() {
if (len > BUF)
printf("len is too big :C\\n");
if (len < BUF)
printf("Clean Value :D No overFLow!!!\\n");
size_t A = (size_t)len;
printf("%zu", A);
memcpy(to, from, len);
return;
}
💡 리눅스용 코드(GCC)
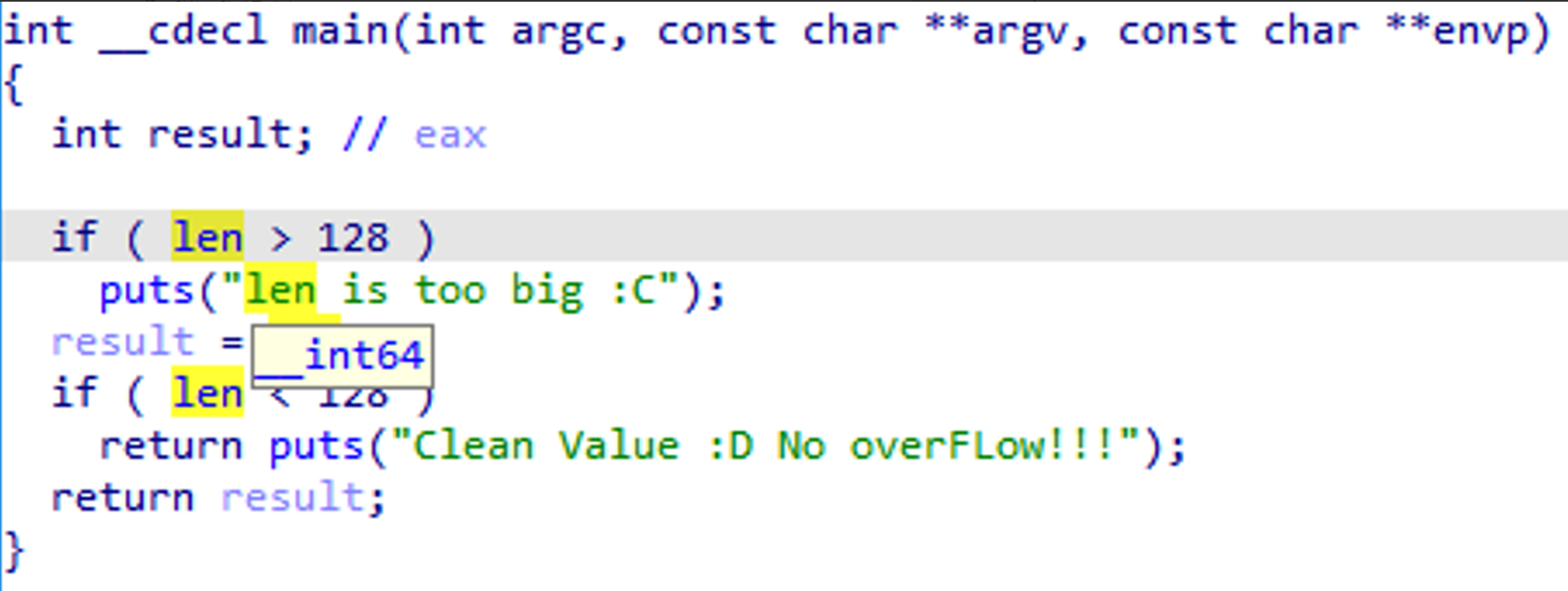
- Buffer Overflow가 발생하는지 안하는지 체크하기 위해 memcpy의 길이 인잣값인 len이 128을 넘는지 안 넘는지 확인하는 코드.
- int와 len의 크기가 같은 32비트 환경이라면(4바이트), -1을 대입해도 0xFFFFFFFF > 0x00000080 이기 때문에 결국에 작동은 하게 된다.
- 왜 0xFFFFFFFF로 바꾸어서(부호 없이) 계산을 하는건데?
- int와 len의 크기가 같은 32비트 환경이라면(4바이트), -1을 대입해도 0xFFFFFFFF > 0x00000080 이기 때문에 결국에 작동은 하게 된다.


- long(32비트 기준 4바이트), unsigned int(4바이트) 의 폭이 32비트에선 4바이트로 동일하므로, long이 unsigned int의 전체 범위(2147483647보다 큰 값)을 담을 수가 없으므로, long은 자동으로 부호 없는 값으로 재해석이 되어야함. 윈도우에서는 long이 4바이트이므로, 위 코드를 컴파일하고 실행해보면 아래처럼 -1을 대입해도 개발자가 의도한대로 오버플로 감지가 잘 작동한다.
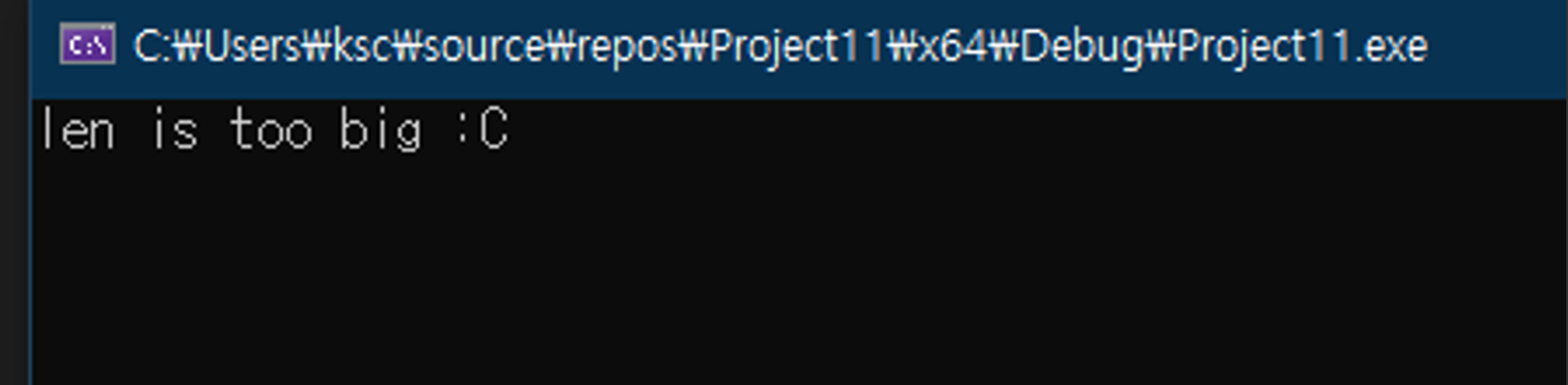
- 컴파일 된 바이너리를 디컴파일 해보면, 우리는 분명 Signed Long타입의 Len을 지정했음에도 불구하고 (Unsigned Int)로 자동 형 변환을 하여 계산하는 것을 볼 수 있다. 아래 그림 참조:
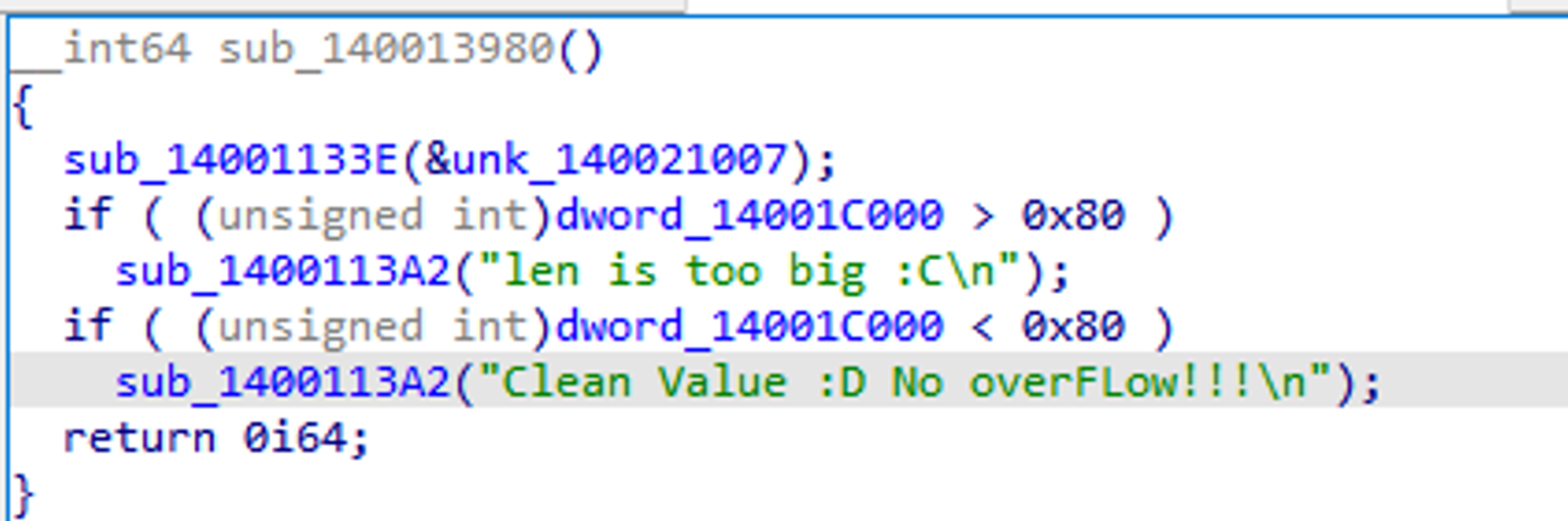
- 리눅스에서는 64비트에서 LONG은 8바이트이므로, -1을 대입하게 되면 아래와 같이 오버플로 감지가 무력화 된다.
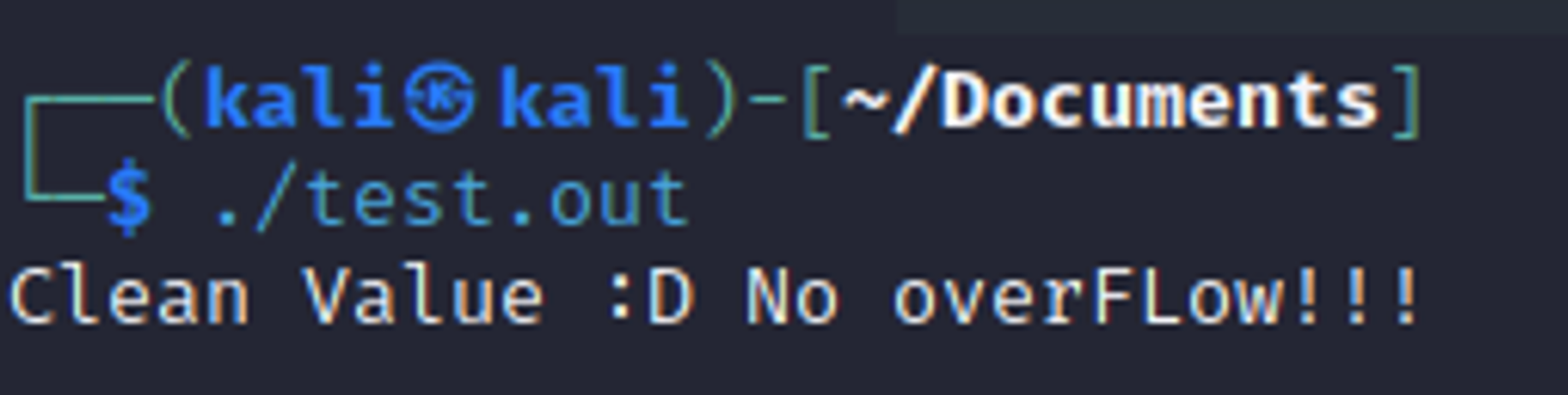
- 리눅스에서 컴파일한 ELF 파일을 디컴파일해보면, 역시 여기서는 Signed Long 타입의 Len이 Unsigned Int타입 Buf의 최대 범위를 담을 수 있으므로 부호화 있는 검사를 하게된다. -1은 128보다 작으므로 검사가 우회된다(__int64)

- 윈도우에서 long을 리눅스 64비트의 long과 동일한 크기를 가지는 long long으로 바꾸고 나서 테스트를 해보면, 리눅스와 동일한 결과를 얻을 수 있다.
#include <stdio.h>
#include <string.h>
#include <malloc.h>
#include <cstdint>
const unsigned int BUF = 128;
long long len = -1;
void main() {
if (len > BUF)
printf("len is too big :C\\n");
if (len < BUF)
printf("Clean Value :D No overFLow!!!\\n");
size_t A = (size_t)len;
printf("%zu", A);
//memcpy(0x0, 0x0, len);
return;
}
💡 윈도우용 코드

memcpy의 3번째 인잣값인 메모리 복사 길이의 타입은 SIZE_T이고, SIZE_T는 앞서 말했듯, 부호화 되지 않는 값을 가지게 된다. len을 size_t로 타입 캐스팅 한 뒤, 출력해보면 128보다 큰 값을 인자로 넘기는 것을 알 수 있다. 이는 오버플로우를 유발하게 된다.
더보기
💡 필자는 현재 이 Signedness Of Comparison을 공부하고 있음에도 처음에 윈도우 환경에서 long long을 long으로 써두고 ‘뭐야;; 왜 안돼??’하고 30분동안 원인을 찾지 못했다. 처음에 디컴파일링을 한 후 자동으로 분기문에서 Unsigned int로 형변환을 하는 것을 보고, 비주얼 스튜디오 컴파일러와 링커의 보안가드(GS)나 코드 최적화 때문에 자동으로 이렇게 짜주는구나~라고 생각했다가, 모든 보안과 최적화 옵션을 꺼도 동일한 결과를 얻어, 문득 데이터 모델이 생각나 올려보니, 윈도우에서는 long이 4바이트고, 리눅스에선 8바이트라는 사실을 기억해냈다. 이렇게 신경쓰고 있는데도 깜빡깜빡하는데, 별로 신경쓰지 않으면서 코드를 짠다면, 아무리 숙련 된 개발자라도 이런 실수를 과연 아예 하지 않을까?라는 생각을 하게되었다.
Effects of a Larger Address Space
- 64비트 환경에서는 32비트 환경과 다르게, 최대 주소 공간의 크기가 4GB(2^32)에서 수십 TB(2^64)까지 증가했기 때문에, 더 많은 메모리를 처리해야 함. 따라서 32비트에서는 구현과 발생이 구조적으로 불가능했던 취약점들이 발생할 수 있음.
Dormant Integer Overflows(Unlimited Loop)
- 더 넓고 큰 메모리 공간(주소 공간) 때문에 더 큰 범위의 변수를 사용하면서 생기는 취약점.

해석:
주소 공간이 클수록
(1) 더 큰 객체를 생성할 수 있고
(2) 더 많은 수의 객체를 사용할 수 있습니다. 따라서 포인터보다 좁은 변수를 사용하여 객체의 크기나 수에 대해 산술 연산을 수행하는 코드는 64비트 플랫폼에서 정수 오버플로우의 후보가 됩니다.
- 예제 코드
unsigned int i;
size_t len = attacker_controlled();
char *buf = malloc(len);
for(i=0; i<len; i++){
*buf++ = get_next_byte();
}
- 위 코드는 LP64/LLP64의 경우에서 unsigned int가 size_t의 width보다 작기 때문에
$$ WM(unsigned int) < WM(size_t), M ∈ {LP64, LLP64}. $$
- 공식이 성립하게 됩니다. 따라서, 이 경우에 for문에서 검사하는 조건인 i < len이라는 조건이 len이 공격자에 의해 unsigned int의 최대 범위 값보다 큰 경우, 절대로 조건식을 만족시킬 수 없게 되어, 무한 루프에 빠지게 됨.
더보기
💡 Boost C++ 라이브러리, Chromium 및 GNU 표준 C++에서 이전에 알려지지 않은 취약점의 예가 이런 주소 공간의 확장으로 인해 발생했음. 이 논문에서 그 예를 밑에서 다루고 있음.
”Vulnerabilities resulting from the large number of objects are typically tied to reference counters with a type smaller than the pointer size. We provide examples of previously un-known vulnerabilities in the Boost C++ Libraries, Chromium and the GNU Standard C++ from this class in Section 5.” -논문 내용 중 발췌-
Dormant Signedness Issue(위 내용에서 이어짐)
더보기
💡 A common occurrence of such dormant signedness issues is the practice of assigning the return value of strlen to a variable of type int. For strings longer than INT_MAX, this results in a negative length. However, on 32-bit platforms, exploiting this type of flaw is deemed unrealistic due to the restricted amount of memory available. On 64-bit platforms, however, strings of this size can be easily allocated by a single process, making it possible to trigger these dormant signedness issues. -논문 내용 중 발췌-
- 32bit에서 불가능 헀던 취약점 발생 요소들이 큰 주소공간으로 인하여, Signedness와 관련 된 취약점이 발생하는 것.
- 대표적 예시로는 strlen 함수의 Ret 값을 int형 변수에 저장하는 과정에서 일어남. Ret 값이 int형 변수의 최대 범위를 넘어갈 경우, 값이 음수가 됨.
- 32비트 환경에서는 int 값을 넘는 문자열을 저장할 수 없다고 생각, 딱히 큰 이슈 발생 X, 그러나 64비트 환경에서는 큰 메모리 공간으로 인해 쉽게 발생 가능.
- 예제 코드:
char buffer[128];
int len = strlen(attacker_str);
if(len >= 128)
return;
memcpy(buffer, attacker_str, len);
$$ Im(<len>) < I < maxIm(unsigned int) $$
- len이 위의 수식을 만족시킬 경우, len은 Signed Int의 최대 범위를 넘어 음수가 되고, 이는 4행의 조건식을 바이패스(우회)함. 그리고 memcpy의 인자로 들어가는 len은 SIZE_T로 타입 캐스팅 되어 Unsigned Int의 최댓값 이하라면 128보다 큰 길이의 메모리를 읽고 쓰는 오버플로우가 발생.
Unexpected Behavior Of Library Functions
- 여러 표준 C라이브러리 함수는 원래 32비트 데이터 모델을 염두에 두고 설계됨.
- 이는 곧 오버플로, Signed 문제에 취약함을 뜻함.
- 몇 몇 함수는 64비트 데이터 모델에 맞게 조정된 것들도 있음.
- 주로 스트링 포매팅 함수의 경우에는 내부에서 SIZE_T로 처리를 한 뒤, 결과값으로 int형으로 반환하는 경우에 취약점이 발생함.
- 문자열을 인쇄하는 함수(fprintf, snprintf, vsnprintf)는 문자열이 INT_MAX(INT 최대범위)를 넘을 수 없다는 가정하에 설계되어있음.
int snprintf(char *s,size_t n, const char *fmt, ...)
- 위 함수는 최대 n바이트를 복사하고 쓰여질 바이트 수를 반환함. 그러나, 64비트환경에서는 확장된 형식의 문자열이 INT_MAX보다 클 수 있으므로 크기를 정수로 반환할 수 없는 경우가 생김. 이 경우 C99 표준에서는 snprintf가 -1을 반환하게 됨.

int pos = 0;
char buf[BUF_LEN +1];
int log(char *str) {
int n = snprintf(buf +pos, BUF_LEN -pos, "%s", str);
if(n > BUF_LEN -pos) {
pos = BUF_LEN;
return -1;
}
return (pos += n);
}
- 위 코드에서 INT_MAX보다 긴 문자열을 입력하면 snprintf는 -1을 반환하게 되고, 이는 곧 n이 -1이 되어 if문을 통과하여 인덱스 값인 pos에 -1을 대입하게 된다. 이는 언더플로우를 유발시키고, 두 번째 log 함수 호출 사이클에 들어가면 스택 메모리를 손상시키게 됨.
더보기
💡 The function copies at most n bytes and returns the number of bytes that would have been written. On 64-bit platforms the expanded format string, however, may be larger than INT_MAX, making it impossible to return its size as an int. In this case the C99 standard demands that snprintf returns a fixed value of −1 [18, Sec. 7.19.6]. In practice, this can result in vulnerabilities when programmers directly make use of the return value to shift pointers. Figure 9 exemplarily shows a vulnerable implementation of a log function that writes messages to a global buffer of BUF_LEN + 1 bytes in size. -논문 내용 중 발췌-
- File Processing에서의 버퍼 오버플로우
- printf와 같은 출력 함수군과 마찬가지로 ftell, fseek 및 fgetpos와 같은 파일 처리를 위한 표준 C 라이브러리 함수는 64비트 정수( 4gb보다 큰 파일)을 처리할 수 없음. 혹은 오작동.
- 이런 문제를 인식한 ms에서 ftello, ftello64, ftelli64의 도입으로 해결함. 그러나 손에 익은 개발자들은 ftell 함수를 더 많이 쓰고 있음.
- 또, ftell 함수는 고용량 파일을 처리할 때, Undocumented Behavior(msdn 문서에 없는 처리)를 함. C99 표준에서는 실패 시 반환 값을 -1로 취하지만, c++ 라이브러리 구현에서는 현재 위치가 LONG_MAX(0xffffffff)를 초과하는 경우엔 0을 반환하므로 의도치 않은 문제발생
-
int i; char *buf; FILE* const f = fopen(filename, "r"); fseek(f, 0, SEEK_END); const long size = ftell(f); buf = malloc(size / 2 + 1); fseek(f, 0, SEEK_SET); for (; fscanf(f, "%02x", &i) != EOF; buf++) *buf = i;- 위 코드에선 ftell을 사용하여 파일의 eof를 구함(끝). 그리고 EOF에 도달할 때 까지 fscanf를 반복적으로 호출하여 바이트 값을 버퍼에 기록함.
- Windows 64비트에서는 ftell 호출이 0을 반환하고 버퍼에 1바이트만 할당되기에 4gb보다 큰 파일을 사용하면 복사 루프에서 프로세스에 할당되지 않는 메모리에 전체 파일을 기록하여 힙을 손상시킴.
더보기
💡 Similar to the printf family of functions, the standard C library functions for processing files, such as ftell, fseek and fgetpos, are not designed to deal with the effects of 64-bit integer numbers, in this case, files larger than 4 Gigabyte. This problem is well known and is addressed by the introduction of 64-bit aware counterparts, ftello, ftello64 or __ftelli64. However, our empirical study shows that ftell still is widely used instead of the better alternatives (Section 4). Furthermore, the function ftell exhibits an undocumented behavior when confronted with large files. It is specified to return the current position of a file pointer as value of type long, which is 32 bit wide on platforms using the LLP64 data model. While the C99 standard specifies a return value of −1 for failures, the Microsoft Visual C++ Runtime Library’s implementation returns 0 if the current position exceeds LONG_MAX (0xffffffff), which gives rise to security problems. -논문 내용 중 발췌-
결론 & 느낀 점
- 64비트로 전환을 하는데, 지금 64비트로의 이식이 몇 십년이 지났음에도 불구하고 잘못 된 Implicit Type Conversions 때문에 debian과 같은 대규모 프로젝트에서도 취약점이 발생하는 것을 보고, “정말 과거의 사례는, 어차피 패치가 되어서 볼 가치가 없다!”라는 사고 방식을 버리고 과거의 사례와 논문을 많이 찾아봐야겠다는 생각을 했다.
- 또, 이런 취약점들을 직접 코드를 짜보고 실습을 하면서, 중간에 Signed of Comparison 실습을 하며 그릇 된 판단을 할 뻔 했는데, 내가 지금 이 취약점을 인지하고 공부하고 있음에도 이런 실수를 하는 것을 보고, ‘현업에 종사하면서 신경 쓸 것이 많을텐데, 절대적으로 안전하게 코딩할 수 있는 사람이 있을까?’라는 생각을 하게 되었고, 이를 밑의 암시적 변환 표를 보면서 불가능하다는 것을 느끼게 되었다.
- 또, Type Conversion과 관련 된 문제들은 대부분 경고가 뜨는 것을 확인했는데(실습 중 내 코드에서), 실 배포 프로그램의 경우 경고가 1000~2000개 가량 뜨다보니 무시하게 되는 것이 당연지사라고 생각함과 동시에, 이런 경고를 조금 더 경각심을 갖게 할 순 없을까? 와 같은 생각을 하게되었다.
- 코드 자체에서 발생하는 취약점이 아닌, 아키텍처와 32-64bit의 차이로 발생하는 취약점을 보고, 정말 하드웨어와 소프트웨어의 상호작용이 취약점 발생에 큰 영향을 미친다는 것을 깨닫고, CS공부를 조금 더 열심히 해야겠다는 생각을 했다.
'Research' 카테고리의 다른 글
| SeedSeeker (1) | 2024.02.18 |
|---|---|
| ComRaceConditionSeeker (0) | 2024.02.13 |
| CodeQL Summary (1) | 2024.02.06 |
| What Is Windows Search DB? (1) | 2023.12.26 |
Contents
소중한 공감 감사합니다